
The support provides facilities in order to configure different kinds of
directories in order to access indices. Both RAM and filesystem directories are
supported thanks to the RAMDirectoryFactoryBean and
FSDirectoryFactoryBean classes.
These two classes allow to handle correctly directories, i.e. they are
closed on the shutdown of the application context of Spring. However, these
entities don't allow the creation new indices when they don't exist. To do that,
you must use an implementation of the IndexFactory interface
like the SimpleIndexFactory class and its create
property. In this case, the index structure is created at the first access.
The following code shows how to configure a RAM directory:
<bean id="ramDirectory" class="org.springframework.lucene.index.support.RAMDirectoryFactoryBean"/> <bean id="indexFactory" class="org.springframework.lucene.index.factory.SimpleIndexFactory"> <property name="directory" ref="ramDirectory"/> <property name="create" value="true"/> </bean>
The following code shows how to configure a filesystem directory:
<bean id="fsDirectory" class="org.springframework.lucene.index.support.FSDirectoryFactoryBean"/> <bean id="indexFactory" class="org.springframework.lucene.index.factory.SimpleIndexFactory"> <property name="directory" ref="ramDirectory"/> <property name="create" value="true"/> </bean>
indirection level. change the strategy of management of resource in the configuration without any change in the code. TODO: IndexFactory and abstraction layer TODO: IndexReaderWrapper/IndexWriterWrapper and abstraction layer
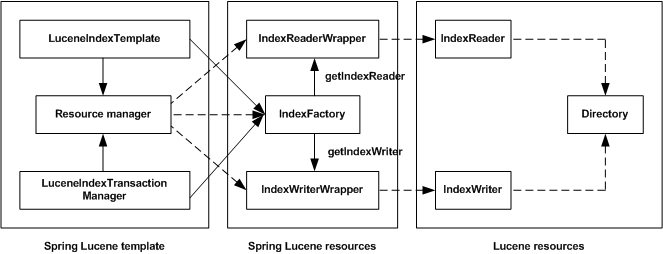
The following code describes the content of the IndexFactory
interface, entity allowing the access to the resources in order to interact with
the index:
public interface IndexFactory { IndexReaderWrapper getIndexReader(); IndexWriterWrapper getIndexWriter(); }
The following table shows the different implementations of the IndexFactory
interface provided by the support:
Table 5.1.
| Implementation | Description |
|---|---|
| SimpleIndexFactory | The simplest and by default implementation of the interface which is based on the
SimpleIndexReaderWrapper and SimpleIndexWriterWrapper
implementations. For each ask of a resource, a new one is created basing on the injected
directory. This implementation supports too the creation of the structure for a new index
and the locking resolution. In this case, you need to use respectively the create
and resolveLock properties. |
| LockIndexFactory | The concurrent implementation based on a lock strategy. This class is a delegating implementation that encapsulate a target index factory. The implementation put a lock at the acquiring of a resource and leave it after its use. |
The IndexFactory interface allows the creation of wrappers
for Lucene reader and writer, respectively of types IndexReaderWrapper
and IndexWriterWrapper. These wrappers provide the same methods
as the target classes but are interface oriented and allow interceptions with proxies.
The following code describes the content of the IndexReaderWrapper
interface:
public interface IndexReaderWrapper { void close() throws IOException; Directory directory(); int docFreq(Term t) throws IOException; Document document(int n) throws IOException; Collection getFieldNames(IndexReader.FieldOption fldOption); TermFreqVector getTermFreqVector(int docNumber, String field) throws IOException; TermFreqVector[] getTermFreqVectors(int docNumber) throws IOException; long getVersion(); boolean hasNorms(String field) throws IOException; boolean isCurrent() throws IOException; int maxDoc(); byte[] norms(String field) throws IOException; void norms(String field, byte[] bytes, int offset) throws IOException; int numDocs(); void setNorm(int doc, String field, byte value) throws IOException; void setNorm(int doc, String field, float value) throws IOException; TermDocs termDocs() throws IOException; TermDocs termDocs(Term term) throws IOException; TermPositions termPositions() throws IOException; TermPositions termPositions(Term term) throws IOException; TermEnum terms() throws IOException; TermEnum terms(Term t) throws IOException; SearcherWrapper createSearcher(); }
The following code describes the content of the IndexWriterWrapper
interface:
public interface IndexWriterWrapper { void addDocument(Document doc) throws IOException; void addDocument(Document doc, Analyzer analyzer) throws IOException; void addIndexes(Directory[] dirs) throws IOException; void addIndexes(IndexReader[] readers) throws IOException; void close() throws IOException; void commit() throws IOException; int docCount(); void deleteDocuments(Term term) throws IOException; Analyzer getAnalyzer(); Directory getDirectory(); PrintStream getInfoStream(); int getMaxBufferedDocs(); int getMaxFieldLength(); int getMaxMergeDocs(); int getMergeFactor(); Similarity getSimilarity(); int getTermIndexInterval(); boolean getUseCompoundFile(); long getWriteLockTimeout(); void optimize() throws IOException; void rollback() throws IOException; void setInfoStream(PrintStream infoStream); void setMaxBufferedDocs(int maxBufferedDocs); void setMaxFieldLength(int maxFieldLength); void setMaxMergeDocs(int maxMergeDocs); void setMergeFactor(int mergeFactor); void setSimilarity(Similarity similarity); void setTermIndexInterval(int interval); void setUseCompoundFile(boolean value); void undeleteAll() throws IOException; void updateDocument(Term term, Document doc) throws IOException; void updateDocument(Term term, Document doc, Analyzer analyzer) throws IOException; }
The selection of the implementations of these interfaces is automatically
done by the implementation of IndexFactory used.
The Lucene indexing support adds other abstractions in order to TODO:
Table 5.2.
| Entity | Interface | Description |
|---|---|---|
| Document creator | DocumentCreator | This entity enables to create a document in order to use it in an indexing process (add or update). |
| Document creator using an InputStream | InputStreamDocumentCreator | This entity enables to create a document using an InputStream (related to a file or others) in order to use it in an indexing process (add or update). |
| Documents creator | DocumentsCreator | This entity enables to create several documents in order to use it in an indexing process (add or update). |
| Reader callback | ReaderCallback | This entity corresponds to a callback interface in order to enable the use of the underlying resource, Lucene reader wrapper, managed by the Lucene support. |
| Writer callback | WriterCallback | This entity corresponds to a callback interface in order to enable the use of the underlying resource, Lucene writer wrapper, managed by the Lucene support. |
The central entity of the support used to execute indexing operations is the Lucene indexing template. It offers several ways to configure indexing according to your needs and your knowledge of the underlying API of Lucene. In this context, we can distinguish three levels to implement indexing in the support:
Using the abstraction level provided by the template;
Using the template with the Lucene entities like Document and Term;
Advanced indexing using the underlying writer instance.
The template allows you to handle several kinds of operations, as described in the following list:
Add operations of document in the index;
Update operations of documents in the index;
Delete operations of documents in the index;
Extra operations like optimizing the index.
We will describe now all these features with these different approaches in the following sections.
The support lets you use directly the Lucene entities like the Document and/ Term classes in order
to manipulate the index. In this case, you have the responsability to create the documents to add or
update and the term. The latters are then passed to the addDocument(s) and
updateDocument(s) methods. In this case, the template has the responsability to
handle the underlying Lucene resources in order to manage the operation.
Related to the adding, the support provides the ability to add only one document with the
addDocument methods. In order to add several documents, addDocuments
methods are provided too.
The following example shows how to create a Lucene document and add it to the index using
the addDocument method:
Document document = new Document(); document.add(new Field("field", "a sample 1", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); getLuceneIndexTemplate().addDocument(document);
The following example shows how to create a list of Lucene documents and add it to the index
using the addDocuments method:
List<Document> documents = new ArrayList<Document>(); Document document1 = new Document(); document1.add(new Field("field", "a sample 1", Field.Store.YES, Field.Index.ANALYZED)); document1.add(new Field("sort", "1", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document1); Document document2 = new Document(); document2.add(new Field("field", "a sample 2", Field.Store.YES, Field.Index.ANALYZED)); document2.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document2); getLuceneIndexTemplate().addDocuments(documents);
In the case of updating documents, the template does a smart update because it checks
if the term corresponds exactly to a document in the case of the updateDocument
method and at least to one document in the case of the updateDocuments method.
The update methods of the template use internally the update methods of the index writer. These latters make a delete of documents based on the specified term and then add the document. Thus, the corresponding methods of the template follow the same mechanism.
The following code shows the use of the updateDocument method:
Document document = new Document(); document.add(new Field("field", "a Lucene sample", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); getLuceneIndexTemplate().updateDocument("field:lucene", document);
The following code shows the use of the updateDocuments method in
order to update several documents with one operation of the template:
List<Document> documents = new ArrayList<Document>(); Document document1 = new Document(); document1.add(new Field("field", "a sample", Field.Store.YES, Field.Index.ANALYZED)); document1.add(new Field("sort", "1", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document1); Document document2 = new Document(); document2.add(new Field("field", "a Lucene sample", Field.Store.YES, Field.Index.ANALYZED)); document2.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document2); getLuceneIndexTemplate().updateDocuments("field:sample", documents);
The delete methods follow the same mechanisms of the update methods according the
checks of documents. Both deleteDocument and deleteDocuments are
provided by the template in order to delete one or more documents.
The following code shows the use of deleteDocument and
deleteDocuments methods:
getLuceneIndexTemplate().deleteDocument("field:lucene"); getLuceneIndexTemplate().deleteDocuments("field:sample");
The template of the Lucene support provides too the ability to use an abstraction layer in the process of Lucene document creation. The main advantages of this approach consists in the handling of resources according to the exception eventually thrown during the document creation. The template supports both simple document creators and input stream based document creators.
The template offers the possibility to use this mechanism with addDocument(s)
and updateDocument(s) methods. We will describe now this feature.
The following code describes the content of the simplest document creator, which provides a simple way to create a Lucene document:
public interface DocumentCreator { Document createDocument() throws Exception; }
The following code shows the way to use the DocumentCreator interface
with the addDocument method of the template:
getLuceneIndexTemplate().addDocument(new DocumentCreator() { public Document createDocument() throws Exception { Document document = new Document(); document.add(new Field("field", "a Lucene sample", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); return document; } });
The InputStreamDocumentCreator interface provides a dedicated entity
in order to create a Lucene document from an InputStream. When using this
interface, you need to specify how to obtain the InputStream and to create
a document from this InputStream.
The template has the responsability to correctly handle the InputStream
and to close it in every case. The following code describes the content of the
InputStreamDocumentCreator interface:
public interface InputStreamDocumentCreator { InputStream createInputStream() throws IOException; Document createDocumentFromInputStream(InputStream inputStream) throws Exception; }
The following code shows the way to use the InputStreamDocumentCreator
interface with the addDocument method of the template:
template.addDocument(new InputStreamDocumentCreator() { public InputStream createInputStream() throws IOException { ClassPathResource resource = new ClassPathResource( "/org/springframework/lucene/index/core/test.txt"); return resource.getInputStream(); } public Document createDocumentFromInputStream(InputStream inputStream) throws Exception { String contents = IOUtils.getContents(inputStream); Document document = new Document(); document.add(new Field("field", contents, Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); return document; } });
Finally the support provides an entity in order to create a list of Lucene documents
to be added, the DocumentsCreator interface. It is similar to the
DocumentCreator interface. The following code describes this interface:
public interface DocumentsCreator { List<Document> createDocuments() throws Exception; }
The following code shows the way to use the DocumentsCreator
interface with the addDocuments method of the template:
template.addDocuments(new DocumentsCreator() { public List<Document> createDocuments() throws Exception { List<Document> documents = new ArrayList<Document>(); Document document1 = new Document(); document1.add(new Field("field", "a Lucene sample", Field.Store.YES, Field.Index.ANALYZED)); document1.add(new Field("sort", "1", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document1); Document document2 = new Document(); document2.add(new Field("field", "a sample", Field.Store.YES, Field.Index.ANALYZED)); document2.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); documents.add(document2); return documents; } });
There are two approaches in order to specify an analyzer during the indexing process. On one hand, you
can set a global analyzer for the template which is used as default analyzer. Thus, with methods without an
analyzer parameter, the global analyzer of the template is used. The following code describes the
use of this approach:
Document document = new Document(); document.add(new Field("field", "a sample 1", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); getLuceneIndexTemplate().addDocument(document);
In the code above, the default analyzer injected in the template is used to add the document. If no analyzer is defined, an exception is thrown.
The support provides too methods with a analyzer parameter. In this case, the
specified analyzer is used instead of the default one. The following code describes the use of this approach
with the same operation:
SimpleAnalyzer analyzer = new SimpleAnalyzer(); Document document = new Document(); document.add(new Field("field", "a sample 1", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); getLuceneIndexTemplate().addDocument(document, analyzer);
The aim of the indexing template is to integrate and hide the use of Lucene API in order to make easy the indexing. This entity provides to the developer all the common operations in this context. However, if you need to go beyond these methods, the template enables to provide the underlying reader and writer entities in order to use it explicitely.
The feature is based on the ReaderCallback and WriterCallback
interfaces described above. When using the entity, you need to implement respectively the
doWithReader and doWithWriter methods which gives you the
underlying instance corresponding the reader and the writer. These latter can be used in your indexing.
The Lucene support continues however to handle and manage these resources. The code below
describes the content of the interface ReaderCallback:
public interface ReaderCallback { Object doWithReader(IndexReaderWrapper reader) throws Exception; }
The code below describes the content of the interface WriterCallback:
public interface WriterCallback { Object doWithWriter(IndexWriterWrapper writer) throws Exception; }
This entity can be used as parameter of the read and writer
methods of the template, as shown in the following code:
getLuceneIndexTemplate().write(new WriterCallback() { public Object doWithWriter(IndexWriterWrapper writer) throws Exception { Document document = new Document(); document.add(new Field("field", "a sample", Field.Store.YES, Field.Index.ANALYZED)); writer.addDocument(document); return null; } });
When using the underlying writer, the analyzer specified for the index template is not used. You need to explicitely specify it on your calls or configure it on the index factory used. In the latter case, the analyzer is set during the creation of the writer.
Like in the other dao supports of Spring, the Lucene support provides a dedicated entity
in order to make easier the injection of resources in the entities implementing Lucene indexing. This entity,
the LuceneIndexDaoSupport class, allows to inject a IndexFactory
and an analyzer. You don't need anymore to create the corresponding injection methods.
In the same time, the class provides too the getLuceneIndexTemplate method
in order to have access to the index template of the support.
The following code describes the use of the LuceneIndexDaoSupport in a class
implementing a search:
public class SampleSearchService extends LuceneIndexDaoSupport { public void indexDocuments() { Document document = new Document(); document.add(new Field("field", "a sample 1", Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("sort", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); getLuceneIndexTemplate().addDocument(document); } }
You can note that the class makes possible to directly inject a configured LuceneIndexTemplate
in Spring.
Lucene has the particularity to allow the creation of only one index writer for an index simultaneously. That's why you need to be careful when indexing documents.
On the other hand, Lucene provides now a support of transactions when updating the index.
The support provides a dedicated implementation of the Spring PlatformTransactionManager
in order to use the transactional support of the framework.
This implementation, the LuceneIndexTransactionManager class, must be
configured using an instance of IndexFactory, as shown in the following
code:
<bean id="indexFactory" class="org.springframework.lucene.index.factory.SimpleIndexFactory"> (...) </bean> <bean id="transactionManager" class="org.springframework.lucene.index.factory.LuceneIndexTransactionManager"> <property name="indexFactory" ref="indexFactory"/> </bean>
This implementation of the PlatformTransactionManager supports read-only
transactions, which allows to extend the scope of a Lucene index reader but doesn't allow the
use of an index writer.