
As for the indexing, the Spring Lucene support provides an abstraction layer
in order to make easier searches with Lucene. The central entities of the layer
are SearcherFactory and LuceneSearchTemplate.
The first allows the creation of search resources according to a dedicated strategy
and the second a convenient support to handle searches.
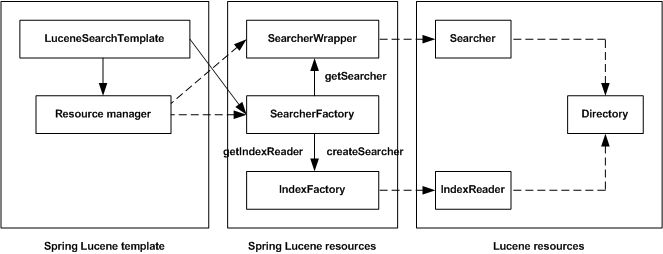
The following figure gives a global map of these entities and their interactions.
You can see that the template is based on the abstraction layer thanks to the
SearchFactory entity.
TODO: SearcherFactory and abstraction layer
public interface SearcherFactory { SearcherWrapper getSearcher() throws IOException; }
TODO: SearcherWrapper and abstraction layer
public interface SearcherWrapper { void close() throws IOException; Document doc(int i) throws IOException; int docFreq(Term term) throws IOException; int[] docFreqs(Term[] terms) throws IOException; Explanation explain(Query query, int doc) throws IOException; Explanation explain(Weight weight, int doc) throws IOException; Similarity getSimilarity(); int maxDoc() throws IOException; Query rewrite(Query query) throws IOException; void search(Query query, Filter filter, HitCollector results) throws IOException; TopDocs search(Query query, int n) throws IOException; TopDocs search(Query query, Filter filter, int n) throws IOException; TopFieldDocs search(Query query, Filter filter, int n, Sort sort) throws IOException; void search(Query query, HitCollector results) throws IOException; void search(Weight weight, Filter filter, HitCollector results) throws IOException; TopDocs search(Weight weight, Filter filter, int n) throws IOException; TopFieldDocs search(Weight weight, Filter filter, int n, Sort sort) throws IOException; void setSimilarity(Similarity similarity); IndexReader getIndexReader(); }
TODO: reopen a searcher
The Lucene search support adds other abstractions in order to modularize the different aspects of searches corresponding to query creation and result extraction and conversion. The following table gives a list of these interfaces.
Table 6.1.
| Entity | Interface | Description |
|---|---|---|
| Hit extractor | HitExtractor | This entity enables to extract informations of documents contained in the result of the search. |
| Query creator | QueryCreator | This entity specifies how to create a Lucene query basing the different supports of the tools. |
| Searcher callback | SearcherCallback | This entity corresponds to a callback interface in order to enable the use of the underlying resource managed by the Lucene support. |
The support leaves developers the choice to use them or to prefer the root entities of Lucene. The use of these interfaces can be done using the template class described underneath.
The central entity of the support used to execute searches is the Lucene search template. It offers several ways to configure search contents according to your needs and your knowledge of the underlying API of Lucene. In this context, we can distinguish three levels to implement searches in the support:
Driven by Lucene query requests as string;
Custom query building using the Query and QueryParser classes and subclasses of Lucene;
Advanced query building using the underlying searcher instance.
We will describe now all these approachs in the following sections.
With this approach, you aren't tied to the Lucene API and can directly use search expressions as query strings. It enables you to use all the powerful of Lucene query string for the searches.
The simplest way to make a search is to specify the query string to the
search method as a parameter. In this case, you need to
explicitely specify the fields corresponding to expressions because no
default field is used. The following code shows how to execute the query string
"field:lucene", i.e. all the documents in the index owing
the field field containing the term "lucene":
List<String> results = getLuceneSearchTemplate().search("field:lucene", new HitExtractor() { public Object mapHit(int id, Document document, float score) { return document.get("field"); } });
The support provides too the ability to specify one or several default fields
for the search. In this case, there is no need to explicitely specify the fields
the search is based on. The following code describes the same search as previously
but using the approach using field a default field:
List<String> results = getLuceneSearchTemplate().search("field", "lucene", new HitExtractor() { public Object mapHit(int id, Document document, float score) { return document.get("field"); } });
When using several default fields, a table of strings can be passed as first parameter
of the search methods.
The Spring Lucene support leaves you the ability to choose the way to build Lucene queries:
Build of queries using directly the Lucene classes;
Use of Spring Lucene abstraction;
In the first case, the built query is given directly to a method of the template. The developer has the responsibility to handle exceptions during the creation independently of the template. The following code shows a sample of this case:
TermQuery query = new TermQuery(new Term("content", "Lucene")); List results = template.search(query, new HitExtractor() { public Object mapHit(int id, DocumentWrapper document, float score) { return document.get("field"); } });
You can choose too to use the QueryCreator interface in order to
integrate the creation of the query in the template. Thus, you can adapt the previous
sample as shows underneath:
List results = template.search(new QueryCreator() { public Query createQuery(Analyzer analyzer) throws ParseException { return new TermQuery(new Term("content", "Lucene")); } }, new HitExtractor() { public Object mapHit(int id, DocumentWrapper document, float score) { return document.get("field"); } });
In both cases, you can use all the Lucene classes dedicated to the creation Lucene queries.
In order to make easier the creation of a parsed query, the support provides the
class ParsedQueryCreator. It helps you to creator a query of
this type using different parameters like token(s) and the text to search. To do this,
the utility class QueryParams is used. The first parameter of its
constructor is the token(s) and the second the text to search.
The following coded shows how to use of this class:
List results = template.search(new ParsedQueryCreator() { public QueryParams configureQuery() { return new QueryParams("field", "lucene"); } }, new HitExtractor() { public Object mapHit(int id, DocumentWrapper document, float score) { return document.get("field"); } });
The aim of the search template is to integrate and hide the use of Lucene API in order to make easy the use of searches. This entity provides to the developer all the common operations in this context. However, if you need to go beyond these methods, the template enables to provide the underlying searcher entity in order to use it explicitely.
The feature is based on the SearcherCallback interface described above.
When using the entity, you need to implement the doWithSearcher method
which gives you the underlying instance of the searcher. This latter
can be used for your search.
The Lucene support continues however to handle and manage this resource. The code below describes the content of this interface:
public interface SearcherCallback { Object doWithSearcher(SearcherWrapper searcher) throws Exception; }
This entity can be used as parameter of a search method of the template, as shown in the following code:
List<String> results = (List<String>) getLuceneSearchTemplate().search(new SearcherCallback() { public Object doWithSearcher(SearcherWrapper searcher) throws Exception { LuceneHits hits = searcher.search(new TermQuery(new Term("field", "lucene"))); List<String> results = new ArrayList<String>(); for (int cpt=0; cpt<hits.length(); cpt++) { Document document = hits.doc(cpt); results.add(document.get("field")); } return results; } });
The Lucene support offers several different strategies in order to extract datas from the result of searches:
Extraction based of the HitExtractor interface, interface provided by the support;
Extraction based of the Lucene HitCollector interface.
The central interface used by the search template in order to return
the documents of a search is the HitExtractor interface.
This interface isn't a Lucene interface and is provided by the support.
It offers a convenient way to implement mapping in order to convert document
into data objects.
In contrary to the Lucene HitCollector interface, the
mapHit method of this interface provides the current document
of the iteration. The built object is automatically added in the collection
returned.
The following code describes the content of the HitExtractor
interface:
public interface HitExtractor { Object mapHit(int id, DocumentWrapper document, float score); }
You can note the use of the DocumentWrapper interface instead
of the Lucene Document class. As this later is final, the
interface allows to use interception on document instances. The common usage is
the ability to use lazy loading on instances of documents. This feature is integrated
in standard into the search template.
The following code shows the use of the HitExtractor interface:
TermQuery query = new TermQuery(new Term("content", "Lucene")); List results = template.search(query, new HitExtractor() { public Object mapHit(int id, DocumentWrapper document, float score) { return document.get("field"); } });
You must be aware that instances of DocumentWrapper can not be returned and
used outside the search template because they are tied to the underlying searcher
instance and this instance can be closed after the return of a method of the template.
If you want to use directly document, you can obtain this instance thanks to the
getTarget method, as shown underneath:
TermQuery query = new TermQuery(new Term("content", "Lucene")); List results = template.search(query, new HitExtractor() { public Object mapHit(int id, DocumentWrapper document, float score) { Document targetDocument = document.getTarget(); return targetDocument; } });
The template offers too the possibility to use the HitCollector
interface of Lucene in order to get results.
The following code describes the content of the HitCollector
interface:
public interface HitCollector { void collect(int doc, float score); }
The following code shows the use of the HitExtractor interface
with the search template:
TermQuery query = new TermQuery(new Term("content", "Lucene")); final List<Integer> results = new ArrayList<Integer>(); List results = template.search(query, new HitCollector() { public void collect(int doc, float score) { results.add(doc); } });
Like in the other dao supports of Spring, the Lucene support provides a dedicated entity
in order to make easier the injection of resources in the entities implementing Lucene searches. This entity,
the LuceneSearchDaoSupport class, allows to inject a SearcherFactory
and an analyzer. You don't need anymore to create the corresponding injection methods.
In the same time, the class provides too the getLuceneSearcherTemplate method
in order to have access to the search template of the support.
The following code describes the use of the LuceneSearchDaoSupport in a class
implementing a search:
public class SampleSearchService extends LuceneSearchDaoSupport { public void searchDocuments() { List<String> results = getLuceneSearchTemplate().search("field:lucene", new HitExtractor() { public Object mapHit(int id, Document document, float score) { return document.get("field"); } }); } }
You can note that the class makes possible to directly inject a configured LuceneSearcherTemplate
in Spring.
TODO